

مقدمه
وقتی صحبت از هوش مصنوعی میشود، تقریباً همه نگاهها به سمت GPU ها میرود؛ همان تراشههای قدرتمندی که به پادشاهان پردازش سنگین شهرت پیدا کردهاند. اگر از علاقهمندان فناوری بپرسید که راز سرعت خیرهکنندهی مدلهای هوش مصنوعی چیست، احتمالاً پاسخ میدهند: «GPU!»
اما حقیقت کمی پیچیدهتر و البته جذابتر است.
پشت صحنهی مدلهای عظیم زبانی، شبکههای عصبی عمیق و سیستمهای هوشمند خودران، معماریهای پیچیدهای از واحدهای پردازشی قرار دارند که هر کدام نقش ویژهای در این اکوسیستم ایفا میکنند. از CPUهای چند هستهای گرفته تا TPUهای تخصصی، از حافظههای پنهان تا مسیرهای ارتباطی پرسرعت بین هستهها همه دست به دست هم میدهند تا هوش مصنوعی نفس بکشد و رشد کند.
در این سفر کوتاه، نگاهی خواهیم انداخت به درون این قلب تپندهی فناوری. میخواهیم بدانیم دقیقاً چه اتفاقی میافتد وقتی یک مدل هوش مصنوعی آموزش داده میشود یا پاسخ شما را تولید میکند. شاید در پایان، شما هم مثل ما باور داشته باشید: هوش مصنوعی فقط GPU نیست!
بخش اول: واحدهای پردازشی را بشناسیم — نقشها در کارخانه هوش مصنوعی
به محض ورود به کارخانهی هوش مصنوعی، با چند شخصیت کلیدی روبهرو میشویم. هر کدام نقش خاصی دارند و نبود هر یک، سرعت و کارایی کل سیستم را پایین میآورد.
CPU — فرماندهی قدیمی و کاردان
CPU یا واحد پردازش مرکزی، همان مغز سنتی کامپیوتر است. کارش مثل سرپرست کلی کارخانه است: وظیفهی هماهنگی و مدیریت وظایف مختلف را بر عهده دارد. هرچند CPU در پردازشهای سنگین یادگیری عمیق به پای GPU نمیرسد، اما هنوز هم برای مدیریت وظایف منطقی، تصمیمگیریهای سریع و آمادهسازی دادهها برای دیگر واحدها بیرقیب است.
بدون CPU، حتی GPU نمیداند از کجا شروع کند!
GPU — قهرمان پردازشهای سنگین
GPU ها همان تیم پرانرژی هستند که در بخشهای سنگین کارخانه کار میکنند. طراحی شدهاند تا حجم عظیمی از دادهها را به صورت موازی پردازش کنند. مدلهای بزرگ هوش مصنوعی مثل GPT یا Stable Diffusion نیاز به هزاران محاسبهی ماتریسی در هر ثانیه دارند و GPU با هستههای متعددش این کار را به شکلی حیرتانگیز انجام میدهد.
اگر CPU مغز کارخانه باشد، GPU مثل بازوان نیرومند آن است.
TPU — متخصص یادگیری ماشین
اینجا با مهندسان متخصص روبرو میشویم: TPU یا Tensor Processing Unit. این واحدها توسط گوگل طراحی شدهاند و هدف اصلیشان بهینهسازی پردازشهای یادگیری ماشین است. آنها عملیات ریاضی سنگین مثل ضرب ماتریسها را با مصرف انرژی کمتر و سرعت بالاتر انجام میدهند.
TPU مثل یک متخصص لیزری است: تمرکز بالا، کارایی بینظیر و سرعت برقآسا.
NPU — مغز کوچک اما چابک
NPU یا Neural Processing Unit به معنای "واحد پردازش عصبی" است. اینها معمولاً در گوشیهای هوشمند یا دستگاههای لبهای (Edge devices) پیدا میشوند. وظیفهشان انجام وظایف هوش مصنوعی با مصرف کم انرژی است، مثلاً تشخیص چهره یا پردازش دستیار صوتی.
NPU مثل کارگرهای سریع و سبکوزن است که در خط مقدم مشغول خدمت هستند.
FPGA و ASIC — تراشههای سفارشی
گاهی اوقات نیاز است کارخانه برای پروژههای خاص، ابزارهای سفارشی بسازد. FPGA و ASIC دقیقاً همین نقش را دارند. FPGA ها قابل برنامهریزیاند و انعطاف زیادی دارند، در حالی که ASIC ها مخصوص یک وظیفه ساخته میشوند و به شدت بهینهاند.
هوش مصنوعی به مثابه دستگاههای مخصوص برای یک محصول ویژه در خط تولید.
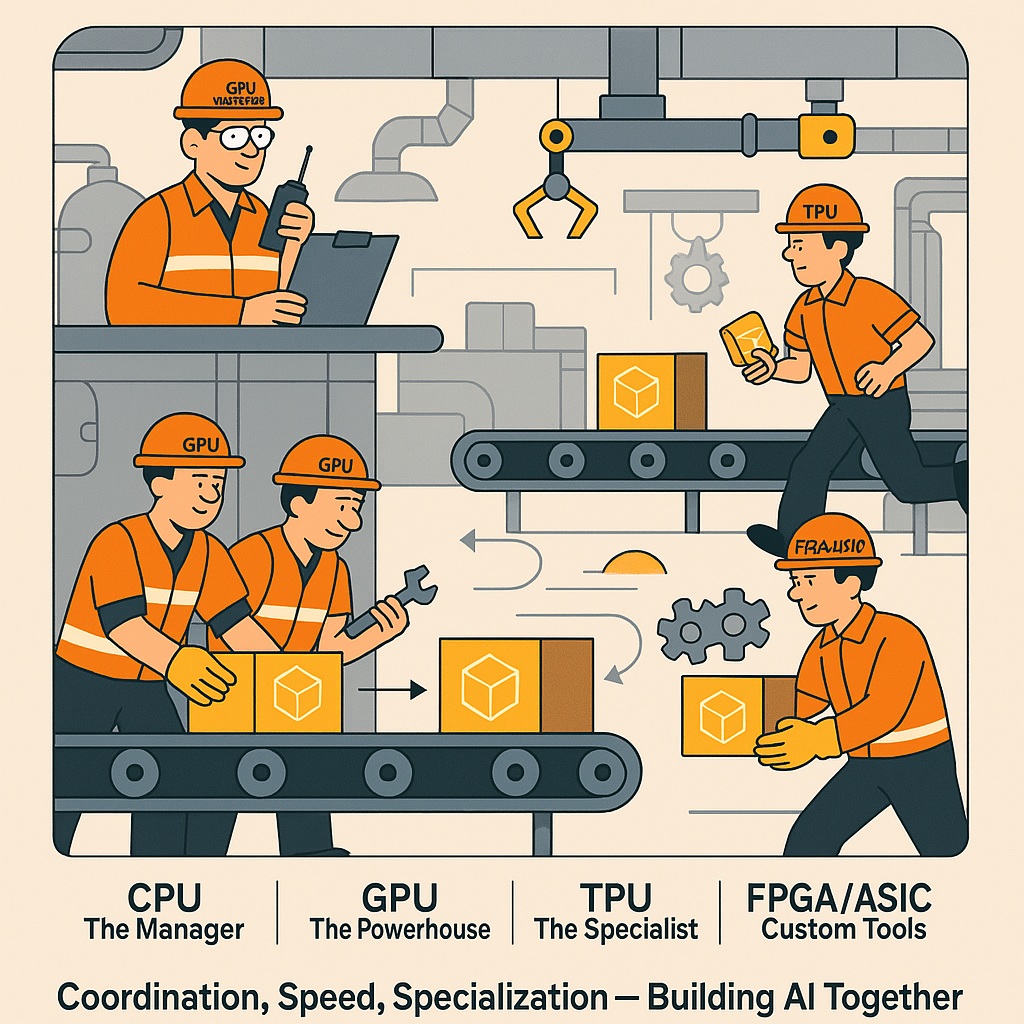 نمای کلی: کارخانه مدرن با لولهها، چرخدندهها، تسمههای نقاله و رباتهای صنعتی.
نمای کلی: کارخانه مدرن با لولهها، چرخدندهها، تسمههای نقاله و رباتهای صنعتی.
- دادهها: به شکل جعبههای داده یا بستههای روشن در حال حرکت روی تسمههای نقاله.
- کارگران کارخانه:
CPU — The Manager / Supervisor- ایستاده روی سکوی فرماندهی با نقشهی کارخانه یا تبلت مدیریتی در دست.
- با بیسیم در حال هماهنگ کردن بخشهای مختلف.
- GPU — Heavy Machine Operators
- گروهی از کارگران قوی که دستهجمعی جعبههای بزرگ داده را روی تسمههای نقاله میگذارند.
- در حال راهاندازی ماشینهای پردازش سنگین.
- TPU — Specialist Engineers
- مهندسین با ابزارهای دقیق که روی جعبههای خاص داده کار میکنند.
- تجهیزات تخصصی کنارشان برای پردازش مدلهای AI.
- NPU — Fast Delivery Workers
- کارگرهای سریع و چابک که بستههای سبکتر داده را به قسمتهای مختلف کارخانه میرسانند.
- FPGA / ASIC — Custom Tool Operators
- تیمی با ابزارهای سفارشی که برای پروژههای خاص کارخانه، دستگاههای ویژهای را تنظیم میکنند.
- جریان داده:
- مسیرهای فلشدار یا تسمههای نقاله نشاندهنده حرکت داده بین بخشها.
- دادهها از CPU به سایر واحدها هدایت میشوند و در نهایت محصول نهایی (نتیجه پردازش AI) خارج میشود.
- عنوان بالای تصویر:
"Inside the AI Factory: Every Unit Matters!" - پیام پایین تصویر:
"Coordination, Speed, Specialization — Building AI Together."
بخش دوم: معماری پشت پرده
اگر واحدهای پردازشی را مثل کارگران و مدیران کارخانه فرض کنیم، حالا وقت آن رسیده که کمی عمیقتر به طراحی خود کارخانه نگاه کنیم؛ یعنی به نقشهی ساختمانی که این کارگران در آن مشغول به کار هستند.
اینجا جایی است که معماری پردازندهها وارد میدان میشود.
هستهها (Cores): قلبهای تپندهی پردازش
هر پردازنده از چندین هسته تشکیل شده است. هر هسته مثل یک کارگر مجزا است که میتواند یک وظیفه را به تنهایی انجام دهد. CPU ها معمولاً تعداد کمی هسته دارند (ولی بسیار قوی)، در حالی که GPU ها هزاران هسته کوچکتر دارند که وظایف را به صورت موازی انجام میدهند.
وقتی مدلهای هوش مصنوعی با هزاران پارامتر اجرا میشوند، موازیسازی مثل معجزه عمل میکند.
واحدهای برداری و ماتریسی: ماشینهای تخصصی محاسباتی
بسیاری از پردازندهها دارای واحدهای برداری هستند که میتوانند چندین داده را در یک دستورالعمل واحد پردازش کنند (SIMD). در هوش مصنوعی، بهخصوص در یادگیری عمیق، بیشتر عملیاتها روی ماتریسها انجام میشود.
GPU ها و TPU ها اینجا میدرخشند چون واحدهای ماتریسی قوی دارند.
تصویر کن: به جای اینکه هر پیچ و مهره را جدا سفت کنیم، یک ابزار بسازیم که دهها پیچ را همزمان ببندد!
حافظههای کش (Cache): انبارهای کوچک و سریع
اگر دادهها هر بار از انبار اصلی (RAM) آورده شوند، سرعت کار بسیار پایین میآید.
حافظههای کش درست کنار هستهها قرار دارند و مثل انبارهای کوچک کنار دست کارگرها هستند. هر چه دادهها به این حافظه نزدیکتر باشند، سرعت پردازش بالاتر میرود.
کشها مثل جعبهابزار شخصی هر کارگر هستند: دم دست و آماده.
پهنای باند و مسیرهای ارتباطی: جادههای کارخانه
اگر ارتباط بین هستهها کند باشد، پردازنده هرچقدر هم قوی باشد، باز هم کار به کندی پیش میرود.
به همین دلیل معماریهای جدید پردازندهها به طراحی مسیرهای ارتباطی پرسرعت بین اجزا اهمیت زیادی میدهند. چیزی که در معماریهای جدید مثل NVLink یا شبکههای روی تراشه (NoC) میبینیم.
جادههای خوب = تحویل سریعتر مواد اولیه و خروج به موقع محصول نهایی!
همانطور که دیدیم، پردازندههای مدرن فقط مجموعهای از هستهها نیستند؛ بلکه یک شهرک صنعتی پیشرفتهاند که طراحی معماری آن، نقش تعیینکنندهای در سرعت و کارایی پردازشهای هوش مصنوعی دارد.
بخش سوم: چرا معماری مهم است؟ بهینهسازی برای هوش مصنوعی
وقتی داده در خط تولید کارخانه حرکت میکند، سؤال اصلی این است: چطور همه این اجزا باید با هم کار کنند تا خروجی هوش مصنوعی، سریع، دقیق و بهینه باشد؟ بیایید دقیقتر ببینیم.
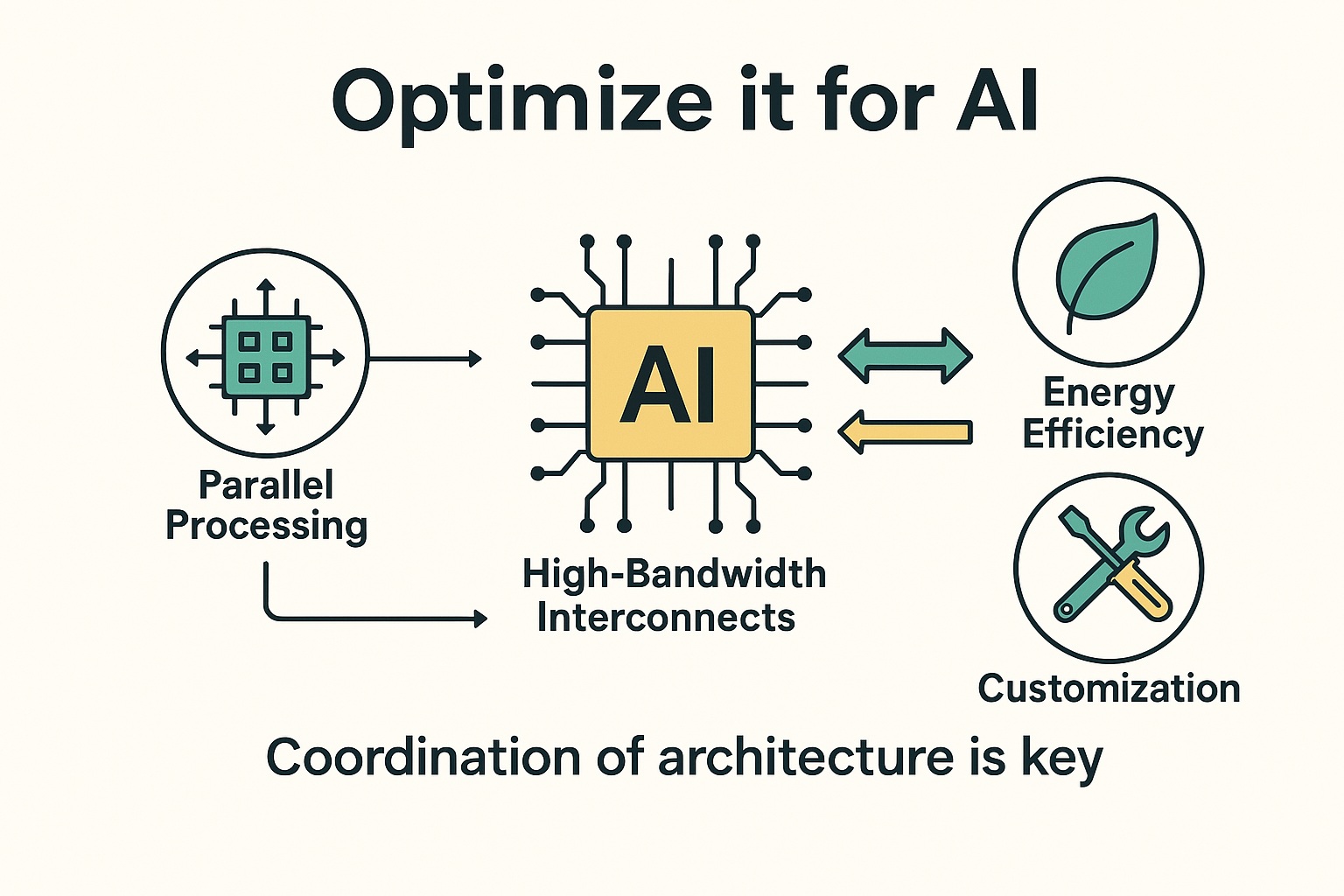
این تصویر با عنوان «بهینهسازی برای هوش مصنوعی»، اصول کلیدی طراحی معماریهای سختافزاری کارآمد برای هوش مصنوعی را به تصویر میکشد. چهار ستون اصلی در اینجا برجسته شدهاند: پردازش موازی برای انجام همزمان حجم بالای محاسبات، ارتباطات با پهنای باند بالا برای انتقال سریع و روان دادهها، بهرهوری انرژی برای حفظ عملکرد بالا با مصرف کمتر برق و سفارشیسازی با تراشههای تخصصی برای وظایف خاص هوش مصنوعی. این تصویر تأکید میکند که قدرت واقعی هوش مصنوعی فقط در توان پردازشی نیست، بلکه در هماهنگی هوشمندانه معماری آن است جایی که هر جزء نقش خود را بهدرستی ایفا میکند تا نتیجهای عالی به دست آید.
بازی با اعداد: پردازشهای عظیم مدلهای هوش مصنوعی
مدلهای مدرن هوش مصنوعی مثل GPT یا Stable Diffusion نیاز به پردازش میلیاردها پارامتر دارند. این یعنی:
- عملیاتهای سنگین ریاضی مثل ضرب ماتریسها
- حجم بالای ورودی/خروجی دادهها
- نیاز به محاسبات موازی گسترده
اینجاست که GPU و TPU با معماری موازی خودشان مثل قهرمان وارد میشوند و محاسبات را به جای یکییکی، دستهای انجام میدهند.
مثال تصویری:
تصور کن به جای اینکه یک کارگر هر جعبه را جدا حمل کند، یک جرثقیل ۱۰۰ جعبه را یکجا بلند کند!
مسیرهای داده: سرعت انتقال حیاتی است
حتی اگر پردازندهها فوقالعاده قوی باشند، اگر دادهها به کندی بین آنها جابهجا شوند، سرعت کل سیستم پایین میآید. به همین دلیل معماریهایی مثل NVLink یا شبکه روی تراشه (NoC) طراحی شدند تا دادهها مثل ماشینهای مسابقهای، با سرعت بالا بین بخشها حرکت کنند.
دادهها مثل سوخت هستند — هر چه سریعتر به مقصد برسند، ماشین هوش مصنوعی سریعتر میدود.
مصرف انرژی: هوش مصنوعی با انرژی کمتر
مدلهای AI به شدت انرژیبر هستند. معماریهای خاص مثل TPU یا ASIC با بهینهسازیهای سفارشی، مصرف انرژی را کاهش میدهند:
- کمتر داغ میشوند
- مصرف برق پایینتر دارند
- و کارایی را حفظ میکنند.
در کارخانه، این یعنی دستگاههایی که با همان کارایی، برق کمتری مصرف میکنند!
سفارشیسازی: ابزار درست برای کار درست
برای کارهای خاص، استفاده از FPGA یا ASIC مثل داشتن ابزار سفارشی است.
- تشخیص چهره در موبایل؟ NPU یا FPGA بهتر عمل میکند.
- آموزش مدل زبانی؟ GPU یا TPU با معماری موازی عالی هستند.
بهینهسازی یعنی انتخاب بهترین ابزار برای بهترین نتیجه.
مثل انتخاب آچار درست برای باز کردن پیچ مخصوص!
هماهنگی برای پیروزی : در دنیای هوش مصنوعی، قدرت واقعی فقط در قویترین پردازندهها نیست، بلکه در هماهنگی معماری و انتخاب درست ابزارهاست. هرچه مسیرهای داده بهتر طراحی شود، هرچه پردازندهها دقیقتر برای کار تخصصیشان بهینه شده باشند، نتیجه نهایی بهتر خواهد بود.
بخش چهارم: نگاه به آینده ، پردازندههای هوش مصنوعی به کجا میروند؟
وقتی به آیندهی پردازندهها برای هوش مصنوعی نگاه میکنیم، تصویر هیجانانگیزی پیش چشم ماست. نه فقط تراشههای قویتر، بلکه معماریهای کاملاً جدید در راه هستند.
چیپهای سفارشیشده برای مدلهای خاص
شرکتهای بزرگی مثل گوگل، آمازون و تسلا در حال طراحی چیپهای اختصاصی برای نیازهای دقیق خود هستند:
- گوگل Dojo (Tesla): طراحی شده برای آموزش مدلهای غولپیکر خودران.
- AWS Inferentia: بهینه برای استنتاج (Inference) سریع و ارزان در سرویسهای ابری.
آینده، چیپهایی است که دقیقاً برای یک کار خاص طراحی شدهاند، مثل ابزار دقیق برای جراحیهای ظریف.
ادغام سختافزار و نرمافزار
مرز بین سختافزار و نرمافزار در حال محو شدن است.
- سختافزارها قابل برنامهریزیتر میشوند.
- مدلهای هوش مصنوعی مستقیماً روی سختافزار بهینه میشوند.
آیندهای را تصور کن که مدل هوش مصنوعی، سختافزار خودش را طراحی میکند!
هوش مصنوعی در لبه (Edge AI)
نیاز به پردازش سریع و آنی در دستگاههایی مثل خودروهای خودران، تلفنهای هوشمند و دوربینهای امنیتی، رشد چشمگیری دارد. واحدهای سبک ولی هوشمند مانند NPU ها، جای خود را در این بازار باز کردهاند.
آینده هوش مصنوعی فقط در دیتاسنترهای غولآسا نیست، بلکه در جیب ما و در هر گوشهی زندگی روزمره خواهد بود.
هوش مصنوعی با سرعتی شگفتانگیز در حال تکامل است. معماریهای آینده نه تنها قویتر و سریعتر خواهند بود، بلکه هوشمندتر، انعطافپذیرتر و دقیقتر طراحی میشوند تا هر چالش را به فرصت تبدیل کنند.
آینده پردازندههای هوش مصنوعی از آن معماریهایی است که بفهمند چگونه بهترین هماهنگی را میان قدرت، سرعت و هوشمندی برقرار کنند.
بخش پنجم: جمعبندی : هوش مصنوعی فقط GPU نیست، بلکه یک هماهنگی فوق العاده بین واحدی است!
وقتی به پشت صحنهی هوش مصنوعی نگاه میکنیم، میبینیم که این فناوری فراتر از انتخاب یک پردازنده یا معماری خاص است. GPUها بدون شک قهرمانهای پردازشهای سنگین هستند. اما بدون CPU که وظایف را هدایت کند، بدون TPUهایی که محاسبات تخصصی را انجام دهند، بدون NPUهایی که سرعت عمل را بالا ببرند و بدون FPGA یا ASICهایی که سفارشیسازی را به اوج برسانند — هوش مصنوعی، فقط مجموعهای از ابزارهای پراکنده خواهد بود.
اما آنچه این سیستم را زنده و هوشمند میکند، هماهنگی میان این اجزاست و هوش مصنوعی، یک مسابقهی تنهایی نیست؛ یک بازی تیمی است که هر بازیکن نقش حیاتی خودش را دارد. هر چه بیشتر این معماریها با هم همسو شوند چه در دیتاسنترهای غولآسا، چه در تلفنهای هوشمند و چه در دستگاههای کوچک لبهای — آیندهای سریعتر، هوشمندتر و کارآمدتر خواهیم داشت.
پس دفعه بعد که صحبت از هوش مصنوعی شد و کسی گفت: "GPU ها همهچیز هستند"، لبخند بزنید و بگویید:
"هوش مصنوعی فقط GPU نیست! این یک تیم بزرگ است، با بازیگران بیشمار."
"AI is not a solo performance — it's an orchestra."
- هوش مصنوعی یک نمایش تکنفره نیست، بلکه یک ارکستر بزرگ است.
- هر پردازنده، هر مسیر داده و هر معماری خاص نقش خود را ایفا میکند.
- هماهنگی میان سرعت، قدرت و هوشمندی، همان چیزی است که این فناوری را به جلو میراند.
- دفعه بعد که به پیشرفتهای هوش مصنوعی فکر میکنید، به تیمی فکر کنید که بیوقفه در پشت صحنه مشغول است از CPU فرمانده گرفته تا GPUهای پرقدرت و مهندسان متخصصی مثل TPU، NPU و FPGA و آینده هوش مصنوعی را همین تیم میسازد....
مهدی عرب زاده یکتا - خط مشی گذار حوزه تحول و حکمرانی دیجیتال
16 فروردین 1404
لیست منابع:
- Jouppi, N. P., Young, C., Patil, N., & Patterson, D. (2017). In-Datacenter Performance Analysis of a Tensor Processing Unit. Proceedings of the 44th Annual International Symposium on Computer Architecture. https://doi.org/10.1145/3079856.3080246
- NVIDIA Corporation. (2023). GPU Accelerated Applications and Workloads. Retrieved from https://www.nvidia.com/en-us/data-center/gpu-accelerated-applications/
- Hennessy, J. L., & Patterson, D. A. (2019). Computer Architecture: A Quantitative Approach (6th ed.). Morgan Kaufmann.
- Google Cloud. (2024). What is TPU? | Cloud TPU Documentation. Retrieved from https://cloud.google.com/tpu/docs
- Tesla, Inc. (2023). Tesla Dojo Technology Overview. Retrieved from https://www.tesla.com/AI
- AWS. (2023). AWS Inferentia and Trainium Chips. Retrieved from https://aws.amazon.com/machine-learning/inferentia/
- ARM Ltd. (2023). Neural Processing Unit (NPU) Explained. Retrieved from https://www.arm.com/technologies/npu
- Xilinx. (2023). FPGA for AI and Machine Learning. Retrieved from https://www.xilinx.com/applications/artificial-intelligence.html
- Borkar, S., & Chien, A. A. (2011). The Future of Microprocessors. Communications of the ACM, 54(5), 67–77. https://doi.org/10.1145/1941487.1941507





دیدگاه خود را بنویسید