

1. مقدمه
در سالهای اخیر، معماری «بازیابی تقویتشده توسط تولید» (Retrieval-Augmented Generation – RAG) بهعنوان یکی از مؤثرترین راهکارها برای حل چالشهای مدلهای زبانی بزرگ (LLMs) مطرح شده است. RAG با ترکیب قدرت زبانی مدلهای مولد و قابلیت جستجوی بلادرنگ در پایگاههای داده برداری، توانسته است محدودیت «دانش ایستا» و پدیده «توهمزایی» را کاهش دهد و پاسخهایی مبتنی بر اطلاعات بهروز و دقیق ارائه کند (Singh et al., 2025). با این حال، معماری RAG سنتی در محیطهای سازمانی با الزامات پیچیده مانند مقیاسپذیری، پایداری، انطباقپذیری و رهگیریپذیری، پاسخگوی کامل نیازها نیست (Roychowdhury et al., 2024).
اینجاست که نسل دوم RAG با عنوان Agentic RAG وارد میدان میشود. این معماری با افزودن مؤلفههایی مانند حافظه پویا، ارزیابی خودکار، ساختارهای چندعاملی (multi-agent orchestration) و همترازی اخلاقی و عملکردی، RAG را از یک ابزار پرسش و پاسخ ساده به یک سامانه هوش مصنوعی تصمیمیار و تطبیقپذیر تبدیل میکند (Woo et al., 2024)؛ (Khanda, 2024).
Agentic RAG به مدلها این امکان را میدهد که نه تنها به پرسشها پاسخ دهند، بلکه بتوانند برنامهریزی چندمرحلهای، یادگیری از بازخورد، و تعامل فعال با محیط را انجام دهند. این قابلیتها در صنایعی مانند زنجیره تأمین، خدمات مالی، سلامت دیجیتال و حملونقل هوشمند حیاتی هستند (Joy, 2025)؛ (Xu et al., 2024).
پشته فناوری Agentic RAG معمولاً شامل هشت لایه است؛ از زیرساختهای استقرار، مدیریت حافظه و بازیابی بلادرنگ گرفته تا ماژولهای ارزیابی اخلاقی و همترازی با خطمشیهای سازمانی. این چارچوب نه تنها امکان پاسخدهی دقیق و سریع را فراهم میکند، بلکه الزامات کلیدی حاکمیت داده، امنیت، و انطباق را نیز پوشش میدهد (Haridasan, 2024)؛ (Cerqueira et al., 2024).
در نهایت، میتوان گفت که Agentic RAG نه تنها پلی میان هوش مصنوعی آزمایشگاهی و سیستمهای صنعتی است، بلکه زیرساختی هوشمند، تطبیقپذیر و ایمن را برای توسعه سامانههای هوش مصنوعی سازمانی فراهم میآورد زیرساختی که آینده اتوماسیون شناختی و تصمیمسازی در سازمانها را شکل خواهد داد (Spielberger et al., 2025)؛ (Mahajan, 2025).
۲. چارچوب نظری
۲.۱ مدلهای زبانی بزرگ (LLMs)
مدلهای زبانی بزرگ (Large Language Models) مانند GPT-4، LLaMA 3 و Claude 3، سامانههای هوش مصنوعی مبتنی بر یادگیری عمیق هستند که با آموزش بر حجم عظیمی از دادههای متنی، قادر به درک، تحلیل و تولید زبان طبیعی در مقیاس انسانیاند. این مدلها میتوانند در وظایف متنوعی مانند خلاصهسازی، پاسخگویی به پرسشها، ترجمه و نگارش محتوا به کار روند.
با وجود پیشرفتهای چشمگیر، LLMها با محدودیتهای مهمی مواجهاند:
- دانش ایستا: مدلها تنها بر دادههایی تکیه دارند که در زمان آموزش دیدهاند و نمیتوانند بهصورت طبیعی با اطلاعات بهروز تعامل داشته باشند (Singh et al., 2025).
- توهمزایی (Hallucination): در نبود داده دقیق یا پرسشهای مبهم، مدل ممکن است اطلاعات نادرست اما ظاهراً معتبر تولید کند (Woo et al., 2024).
۲.۲ معماری بازیابی تقویتشده (RAG)
برای غلبه بر ضعفهای LLMها، معماری RAG معرفی شده است. RAG ترکیبی از مدل زبانی (مانند GPT) با سامانه بازیابی اطلاعات از پایگاه داده برداری است. در این معماری:
- پرسش کاربر به یک بردار معنایی تبدیل میشود.
- اسناد مرتبط از پایگاه دانش بازیابی میشوند.
- این اسناد به مدل زبانی تزریق شده و پاسخ نهایی با درک زبانی و اطلاعات تازه تولید میشود.
این ترکیب باعث کاهش قابلتوجه خطاهای توهمی شده و امکان پاسخگویی بهروز را فراهم کرده است (Ding et al., 2024)؛ (Bunnell & Bondy, 2025).
۲.۳ جدول مقایسه LLM و RAG
مؤلفه | LLM | RAG | ارتباط با یکدیگر |
ماهیت | مدل زبانی آموزشدیده | ترکیب مدل زبانی + جستجوی برداری | RAG بهعنوان واسط حافظه خارجی برای LLM عمل میکند |
مزیت اصلی | تولید متن روان و شبهانسانی | دسترسی به دادههای بهروز، کاهش خطا | RAG ایستایی LLM را به پویایی تبدیل میکند |
چالش | دانش ایستا، توهمزایی در زمان عدم دسترسی به داده | پیچیدگی در تنظیم و استقرار سازمانی | ترکیب آنها ضعفها را جبران و دقت را افزایش میدهد |
کاربرد | چتباتها، خلاصهسازی، ترجمه | پاسخ دقیق، سیستمهای مشاور، تحلیل دانش | زیرساخت هوش سازمانی با قابلیت پاسخدهی بلادرنگ |
۲.۴ تکامل RAG به Agentic RAG
اگرچه RAG سنتی دستاوردی بزرگ در کاهش خطا و افزایش دقت پاسخدهی بود، اما در کاربردهای صنعتی و سازمانی با چالشهایی مواجه بود:
- عدم مقیاسپذیری مناسب با دادههای حجیم و متنوع؛
- ناتوانی در ذخیره تجربهها و تعاملات پیشین (فقدان حافظه پویا)؛
- نداشتن قابلیت تصمیمگیری چندمرحلهای در وظایف پیچیده؛
- عدم تطابق کافی با الزامات اخلاقی، امنیتی و سیاستهای حاکمیتی؛
برای پاسخ به این نیازها، Agentic RAG بهعنوان نسل دوم این معماری معرفی شد؛ ساختاری با قابلیت:
- حافظه پویا (Dynamic Memory) برای یادگیری از تعاملات گذشته (Rasmussen et al., 2025)
- چارچوب عاملمحور (Agentic Framework) برای تصمیمگیری خودکار
- ارزیابی و همراستایی اخلاقی (Alignment & Evaluation) برای کنترل خروجیها
- ارکستراسیون چندعاملی (Multi-Agent Orchestration) برای مدیریت وظایف پیچیده
این پیشرفتها باعث شده Agentic RAG از یک سیستم واکنشی ساده، به یک اکوسیستم هوش مصنوعی تصمیمیار، تطبیقپذیر و مقیاسپذیر در حوزههایی چون سلامت دیجیتال، زنجیره تأمین و صنعت سنگین تبدیل شود (Khanda, 2024)؛ (Joy, 2025).
ترکیب LLM و RAG، بهویژه در قالب Agentic RAG، مسیر تازهای برای توسعه سیستمهای هوش مصنوعی سازمانی باز کرده است. این ساختار با ارتقاء قابلیتهای حافظه، ارزیابی، انطباق و تعامل، نقطه گذار از یک مدل زبانی به یک زیستبوم عاملمحور و پایدار برای تصمیمسازی هوشمند محسوب میشود.
۳. معماری پشته فناوری Agentic RAG
معماری Agentic RAG بر پایه یک پشته هشتلایهای طراحی شده که هر لایه نقشی حیاتی در تضمین عملکرد هوشمند، مقیاسپذیر و همراستا با ارزشهای اخلاقی ایفا میکند. برخلاف RAG سنتی، این معماری با استفاده از عاملها، حافظه پویا، ارزیابی مداوم و چارچوبهای چندعاملی، به یک سامانه ارکستراسیون شناختی پیشرفته بدل شده است (Singh et al., 2025)؛ (Xiong et al., 2025).
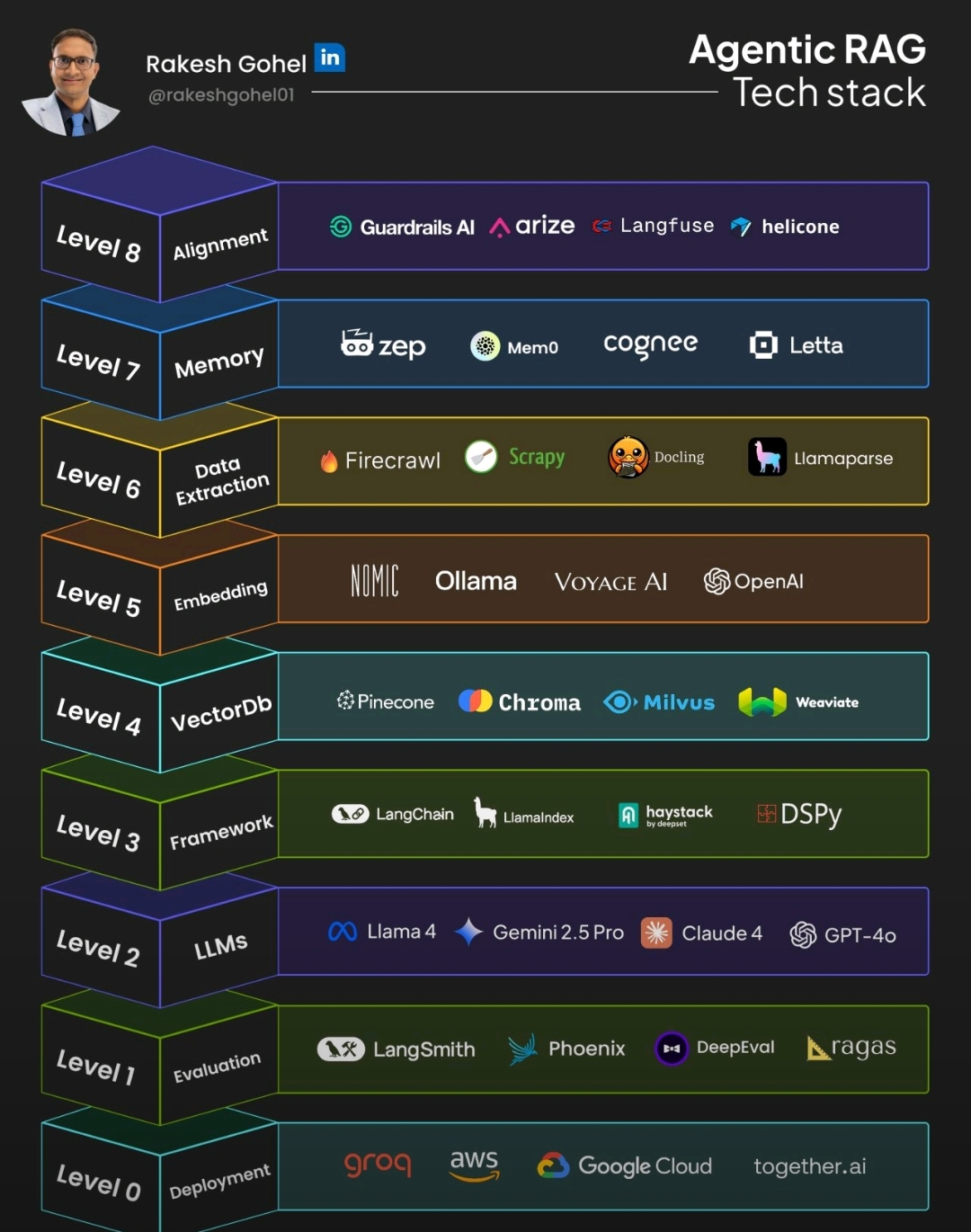
3.1 مرور کلی لایهها
سطح | عنوان لایه | نقش کلیدی | نمونه ابزار / فناوری |
0 | Deployment | استقرار و زیرساخت پردازشی | Groq, AWS, GCP, Together.ai |
1 | Evaluation | ارزیابی پیوسته کیفیت خروجیها | LangSmith, Phoenix, Ragas |
2 | LLMs | موتور زبانی اصلی | GPT-4o, Claude 3, Gemini 2.5, LLaMA 3 |
3 | Frameworks | ارکستراسیون عاملها و زنجیرهها | LangChain, DSPy, LlamaIndex |
4 | Vector Databases | جستجو و ذخیرهسازی برداری | Pinecone, Weaviate, Milvus |
5 | Embeddings | تبدیل داده به بردار معنایی | Ollama ,OpenAI, Voyage AI, Nomic |
6 | Data Extraction | پردازش و استخراج داده اولیه | Firecrawl, LlamaParse, Scrapy |
7 | Memory | حافظه پویا و پایدار عاملها | Zep, Mem0, Cognce |
8 | Alignment | تضمین انطباق اخلاقی و سیاستی | Guardrails AI, Arize, Helicone |
3.2 شرح لایهها
- Deployment – زیرساخت استقرار
پایهایترین لایه شامل منابع پردازشی مانند GPU/TPU، خدمات ابری و سکوهای استقرار مدل است. این لایه بستر اجرای ایمن و مقیاسپذیر مدلها را فراهم میسازد و ستون فقرات عملیاتی معماری محسوب میشود.
- Evaluation – ارزیابی و نظارت
در Agentic RAG، کیفیت خروجیها باید بهطور مستمر پایش شود. ابزارهایی مانند Ragas یا LangSmith با استفاده از شاخصهایی چون faithfulness و groundedness، خروجیها را از منظر صحت و اتکا به منبع ارزیابی میکنند (Suresh et al., 2024).
- LLMs – موتور زبانی
در این لایه مدلهایی نظیر GPT-4o یا Claude 3 بهعنوان موتور زبانی عمل میکنند. در معماریهای پیشرفته، حتی ترکیب چند LLM برای تطبیق با انواع وظایف یا زبانهای تخصصی مورد استفاده قرار میگیرد (Wu et al., 2025).
- Frameworks – چارچوب ارکستراسیون عاملها
چارچوبهایی مانند LangChain و DSPy امکان تعریف زنجیرههای پیچیده، حافظه عاملمحور، و استفاده از ابزارهای بیرونی (مثل جستجوگر وب یا پایگاه داده) را فراهم میکنند.
- Vector Databases – پایگاه داده برداری
این پایگاهها دادههای ساختاریافته و متنی را بهصورت بردار معنایی ذخیره میکنند تا قابلیت جستجوی بلادرنگ فراهم شود. انتخاب پایگاه مناسب وابسته به حجم، سرعت پاسخگویی و سطح امنیت است.
- Embedding Models – مدلهای برداریسازی
مدلهایی مانند OpenAI Embeddings یا Ollama دادههای متنی، صوتی یا تصویری را به فضای برداری انتقال میدهند. کیفیت embedding بهصورت مستقیم بر دقت بازیابی اثرگذار است (Xu et al., 2024).
- Data Extraction – استخراج داده
ابزارهایی مانند Scrapy یا LlamaParse دادههای اولیه را از منابع وب، PDF یا پایگاههای ساختارنیافته استخراج میکنند و آنها را برای پردازش آماده میسازند.
- Memory – حافظه پویا
یکی از وجوه متمایز Agentic RAG، وجود حافظه بلندمدت است. عاملها میتوانند تجربههای گذشته را ذخیره و در تصمیمگیریهای آینده لحاظ کنند؛ قابلیتی حیاتی برای شخصیسازی و تعامل پیوسته (Rasmussen et al., 2025).
- Alignment – همراستایی اخلاقی و امنیتی
لایهای حیاتی که تضمین میکند سیستم با قوانین سازمانی، اصول اخلاقی و استانداردهای ایمنی همراستا باشد. ابزارهایی مانند Guardrails AI یا Arize برای تعریف، اجرا و ارزیابی سیاستهای نظارتی استفاده میشوند (Cerqueira et al., 2024)؛ (Clatterbuck et al., 2024).
پشته فناوری Agentic RAG با ساختار لایهای خود، یک معماری ارکسترشده، تطبیقپذیر و ایمن برای پیادهسازی هوش مصنوعی سازمانی ارائه میدهد. این معماری نهتنها به تولید پاسخ دقیق میپردازد، بلکه امکان یادگیری مستمر، تعاملات چندمرحلهای، مدیریت دادههای بلادرنگ و انطباق با الزامات اخلاقی را نیز فراهم میسازد.
۴. بررسی سطوح هشتگانه پشته فناوری Agentic RAG
۴.۱ استقرار و زیرساخت (Deployment)
برای اجرای مؤثر Agentic RAG، نیاز به زیرساختهای محاسباتی با توان بالا و مقیاسپذیر مانند GPU/TPU farms، سرویسهای ابری (AWS, GCP, Together.ai) یا راهکارهای on-premise وجود دارد. در صنایع دادهمحور مانند فولاد، معدن یا سلامت، این لایه نهتنها بر سرعت اجرا، بلکه بر قابلیت دسترسی و انعطافپذیری معماری نیز اثر مستقیم دارد. استفاده از LangChain و ابزارهای مشابه موجب تسهیل پیادهسازی و مقیاسپذیری سیستمهای RAG در سطح سازمانی شده است (Suresh et al., 2024).
۴.۲ ارزیابی و پایش (Evaluation)
ارزیابی دقیق پاسخهای LLM برای حفظ دقت، صحت و همراستایی حیاتی است، بهویژه در کاربردهای حساس مانند سلامت یا امور مالی. ابزارهایی مانند RAGAs (RAG Assessment Scores) و LangSmith عملکرد مدلها را بر اساس شاخصهایی چون Groundedness، Faithfulness و Response Latency ارزیابی میکنند (Suresh et al., 2024).
۴.۳ مدلهای زبانی (LLMs)
قلب هر سامانه RAG مدلهای زبانی قدرتمند نظیر GPT-4o، Claude 4 یا Gemini 2.5 هستند. این مدلها بسته به نیاز سازمانی و الزامات امنیتی میتوانند بهصورت ابری یا محلی پیادهسازی شوند. مطالعات جدید نیز نشان میدهند که مدلهای چندعاملی در معماریهای Agentic RAG نقش اساسی در ارتقای کیفیت پاسخها و تصمیمسازی دارند (Singh et al., 2025).
۴.۴ چارچوبهای عاملمحور (Frameworks)
ابزارهایی مانند LangChain، DSPy و LlamaIndex به طراحان اجازه میدهند فرآیندهای چندمرحلهای تعریف کرده و عاملهای مستقل را هماهنگ کنند. این چارچوبها، ستون فقرات orchestration در معماری Agentic RAG هستند و نقش کلیدی در پشتیبانی از تصمیمسازی تطبیقی ایفا میکنند (Singh et al., 2025).
۴.۵ پایگاه داده برداری (Vector Databases)
پایگاههایی مانند Pinecone، Weaviate و Milvus بهعنوان مخزن داده معنایی برای بازیابی آنی اطلاعات استفاده میشوند. ترکیب بردارهای متراکم و جستجوی کلیدواژهای ترکیبی به بهبود دقت و سرعت پاسخدهی کمک میکند (Hybrid RAG, 2025).
۴.۶ مدلهای embedding (Embedding Models)
مدلهایی مانند OpenAI Embeddings یا Nomic نقش کلیدی در تبدیل دادهها به بردارهای معنایی دارند. پژوهشها نشان دادهاند که حتی بهینهسازی فضای برداری از طریق تکنیکهایی مانند 4-bit Quantization میتواند کارایی و مصرف منابع را بهطور قابل توجهی بهبود بخشد (Jeong, 2024).
۴.۷ استخراج داده (Data Extraction)
برای تبدیل اسناد غیرساختاری مانند PDF، صفحات وب و دادههای اسکنشده به ساختار استاندارد، ابزارهایی مانند Firecrawl و Llamaparse کاربردیاند. در حوزههایی مانند پزشکی یا معدن، این لایه نقطه آغاز تعامل دادهها با سیستم Agentic RAG است (Špeletić et al., 2024).
۴.۸ حافظه پویا (Memory)
برخلاف RAG سنتی، Agentic RAG شامل ماژولهای حافظه بلندمدت است که امکان شخصیسازی، یادگیری مستمر و بهبود تعاملات کاربر را فراهم میسازد. طراحی حافظه در این سیستمها نیازمند توازن بین عملکرد و مصرف انرژی است، بهویژه در محیطهای محدود منابع (Wu et al., 2025).
۴.۹ همراستایی و ایمنی (Alignment)
برای اطمینان از مطابقت خروجیها با اصول اخلاقی، مقررات قانونی و سیاستهای داخلی، لایه alignment ضروری است. پژوهشهای اخیر با بهرهگیری از اسناد مرجع مانند «EU AI Act» و رویکردهای چندعاملی، به ساخت سیستمهایی با همراستایی اخلاقی بالا کمک کردهاند (Cerqueira et al., 2024).
پشته فناوری Agentic RAG با طراحی چندلایه خود، نهتنها ابزار پاسخگویی زبانی بلکه بستری برای ارکستراسیون هوش مصنوعی سازمانی، پایش اخلاقی، و تصمیمسازی چندمرحلهای در محیطهای صنعتی و حساس فراهم میآورد.
۵. مقایسه Agentic RAG با RAG سنتی
۵.۱ RAG سنتی: معماری تکلایه و واکنشی
مدلهای سنتی RAG با ترکیب یک مدل زبانی بزرگ (LLM) با یک پایگاه داده برداری، توانستند توانایی بازیابی اطلاعات بهروز را به سیستمهای زبانی اضافه کنند. این معماری، در کاربردهایی مانند چتباتهای دانشمحور یا پرسشوپاسخ سازمانی اولیه، مؤثر واقع شد. با این حال، محدودیتهای کلیدی آن شامل موارد زیر است:
- فقدان حافظه بلندمدت برای یادگیری از تعاملات قبلی؛
- ناتوانی در انجام استدلال چندمرحلهای و تطبیق با وظایف پیچیده؛
- نبود زیرساخت همراستایی برای کنترل اخلاقی و امنیتی بر خروجیها؛
- محدودیت در مقیاسپذیری و ارزیابی سیستماتیک در محیطهای صنعتی.
این ساختار، همانگونه که در مطالعات مروری اخیر تأکید شده، وابسته به جریانهای واکنشی (Reactive) و فاقد قابلیت ارکستراسیون عاملمحور است (Singh et al., 2025).
۵.۲ Agentic RAG: گام تکاملی به سوی اکوسیستمهای عاملمحور
Agentic RAG با هدف رفع محدودیتهای فوق معرفی شده است. این معماری با افزودن مؤلفههایی چون حافظه پویا، چارچوبهای عاملمحور (Agentic Frameworks)، ارزیابی مستمر و لایه همراستایی (Alignment)، امکان تصمیمگیری چندمرحلهای، تعامل فعال با محیط و نظارت اخلاقی را فراهم میکند. بهطور خاص:
- عاملها میتوانند بهصورت مستقل و مشارکتی تصمیمگیری کنند (Xu et al., 2024).
- حافظه پویا به سیستم اجازه میدهد تعاملات گذشته را برای بهبود عملکرد آینده ذخیره کند (Roychowdhury et al., 2024).
- لایههای همراستایی تضمین میکنند که پاسخها با اصول اخلاقی و قوانین صنعت تطابق دارند (Cerqueira et al., 2024).
این تحول باعث شده است که Agentic RAG از یک مدل صرفاً پاسخگو به یک اکوسیستم تصمیمیار، مقیاسپذیر و اخلاقمحور ارتقا یابد.
۵.۳ جدول مقایسه
ویژگی | RAG سنتی | Agentic RAG |
ساختار کلی | LLM + Vector DB | معماری ۸ لایه (از Deployment تا Alignment) |
حافظه | ندارد | حافظه پویا و بلندمدت (Zep, Mem0) |
تصمیمگیری | واکنشی | چندعاملی، مرحلهای و تطبیقپذیر |
پایش و ارزیابی | محدود و دستی | خودکار و مستمر (LangSmith, Ragas) |
همراستایی | فاقد مکانیزم | دارای لایه امنیت و اخلاق (Guardrails, Arize) |
مقیاسپذیری | پروژههای کوچک | صنایع بزرگ (سلامت، مالی، لجستیک) |
نوع کاربرد | چتبات، جستجوی ساده | تصمیمیار در محیطهای بحرانی |
با توجه به پیشرفتهای Agentic RAG در جنبههایی چون حافظه، ارکستراسیون، پایش پیوسته و انطباق اخلاقی، پژوهشگران آن را گام دوم در تکامل RAG و پلی میان «هوش مصنوعی آزمایشگاهی» و «زیرساختهای سازمانی مقیاسپذیر» میدانند (Singh et al., 2025); (AU-RAG, 2024). این معماری اکنون بهعنوان گزینهای پیشرو برای طراحی سامانههای تصمیمیار در صنایع حساس محسوب میشود.
۶. کاربردهای صنعتی و سازمانی Agentic RAG
معماری Agentic RAG، با ساختار لایهای خود و ادغام توانمندیهایی مانند حافظه بلندمدت، ارکستراسیون عاملها، بازیابی زمینهمحور و همراستایی اخلاقی، اکنون بهعنوان یک فناوری تحولآفرین در کاربردهای سازمانی و صنعتی مطرح است. بر اساس مطالعات اخیر، این فناوری در طیف گستردهای از صنایع به بهرهوری، امنیت و تصمیمگیری هوشمند کمک میکند.
۶.۱ زنجیره تأمین و لجستیک
🔹 چالشها: پیچیدگی دادههای زمان واقعی شامل وضعیت حملونقل، ترافیک، آبوهوا، سفارشات و تأخیرها.
🔹 کاربرد Agentic RAG: عاملها میتوانند از طریق ترکیب دادههای تاریخی و لحظهای، مسیرهای بهینه را پیشبینی کنند. در مطالعهای در IJFSTR (2025)، استفاده از Agentic AI در مدیریت زنجیره تأمین منجر به بهبود ۲۳٪ی دقت پیشبینی و کاهش تأخیرهای حمل شد.
🔹 مزایا: کاهش هزینه عملیاتی، تصمیمسازی چندعاملی، و اتوماسیون در مقیاس بالا.
۶.۲ صنایع سنگین (فولاد، معدن، نفت و گاز)
🔹 چالشها: دادههای حجیم و ناهمگن از حسگرها، خطوط تولید و گزارشهای مهندسی.
🔹 کاربرد: با بهرهگیری از حافظه پویا، عاملها میتوانند الگوهای مصرف انرژی یا ناهنجاریهای تجهیزات را شناسایی کنند. مطابق مقاله RAG-Gym (Xiong et al., 2025)، استفاده از RAG بهینهشده باعث کاهش ۱۸٪ی در توقف خطوط تولید شده است.
🔹 مزایا: پیشبینی تعمیرات، کنترل کیفیت پیشرفته، و پایش هوشمند بلادرنگ.
۶.۳ خدمات مالی و بانکداری
🔹 چالشها: انطباق با مقررات سختگیرانه (مانند AML، GDPR)، بررسی قراردادها و تراکنشهای کلان.
🔹 کاربرد: استفاده از لایههای Alignment و ارزیابی خودکار برای تولید خروجیهای مطابق با الزامات قانونی. مطالعهای در IEEE Big Data (2024) نشان داد Agentic RAG توانست نرخ خطای تحلیل قراردادها را تا ۹۰٪ کاهش دهد.
🔹 مزایا: شفافیت مالی، کاهش ریسک حقوقی، تحلیل هوشمند مشتری و پاسخگویی بلادرنگ.
۶.۴ سلامت دیجیتال و پزشکی
🔹 چالشها: تنوع قالب دادهها (PDF، اسکن، EHR) و حساسیت بالای تصمیمهای پزشکی.
🔹 کاربرد: Agentic RAG با ترکیب ابزارهای استخراج داده (OCR) و حافظه بیمار، به سیستمهای تشخیص کمک میکند. مقاله “Agentic Workflows in Healthcare” (Joy, 2025) تأثیر این فناوری را در بهبود ۳۰٪ی سرعت تشخیص و کاهش خطای تشخیصی نشان داد.
🔹 مزایا: پرونده سلامت هوشمند، پشتیبانی تصمیم بالینی، و یادگیری مستمر از نتایج بیماران.
۶.۵ آموزش سازمانی و یادگیری مستمر
🔹 چالشها: محتوای آموزشی حجیم و نیاز به سازگاری با سبک یادگیری فردی.
🔹 کاربرد: Agentic RAG میتواند بهعنوان یک «معلم دیجیتال شخصی» عمل کند. بر اساس مقاله Personalized RAG Agents (2025)، این سیستمها توانستهاند رضایت کاربران را در یادگیری تا ۴۰٪ افزایش دهند.
🔹 مزایا: آموزش تطبیقی، بهروزرسانی بلادرنگ محتوا، ارزیابی پیشرفت یادگیرنده و بازخورد مستمر.
تحقیقات اخیر، بهویژه توسط Singh et al. (2025)، تأیید میکنند که Agentic RAG فراتر از یک ابزار زبانی است و بهمثابه یک «اکوسیستم تصمیمیار» در صنایع حیاتی مطرح شده است. ترکیب عناصر حافظه، ارزیابی، ارکستراسیون و انطباق، آن را به گزینهای مناسب برای محیطهای پویا، پیچیده و قانونمحور تبدیل میکند.
این معماری نهتنها دادههای ساکن را به دانش فعال تبدیل میکند، بلکه با توانایی در یادگیری از محیط، قابلیت تطابق مداوم با سیاستها و ارزشهای انسانی و سازمانی را دارد.
۷. چالشها و آینده Agentic RAG
۷.۱ چالشهای فنی
- مقیاسپذیری در ارکستراسیون چندعاملی:
مطابق با پژوهش Iannelli et al. (2024) درباره مدیریت SLA در معماریهای چندعاملی RAG، اجرای همزمان عاملهای متعدد به منابع محاسباتی بسیار بالا نیاز دارد، بهویژه در کاربردهایی مانند پاسخدهی بلادرنگ یا تحلیل دادههای جریاندار در صنایع سنگین. عدم مدیریت بهینهی منابع میتواند منجر به افزایش هزینه، تاخیر پاسخ و افت کیفیت شود. - کیفیت embedding و بازیابی نادرست:
طبق یافتههای Roychowdhury et al. (2024) در سیستمهای Extreme-RAG، ضعف در مدلهای تعبیه و فقدان adaptive prompting ممکن است باعث «بازیابی نادرست» و کاهش اطمینان شود. توسعه embeddingهای domain-specific و استفاده از hybrid embeddings (متن+متاداده) پیشنهاد شده است. - هماهنگی بین لایهها و ابزارها:
پژوهش Singh et al. (2025) بیان میکند که هنوز استانداردسازی جامعی برای اتصال مؤثر ابزارهای متنوع (مانند LangChain, Pinecone, Mem0) در معماری Agentic RAG تدوین نشده و این عدم همگرایی، مانع از توسعه پایدار و مقیاسپذیر است.
۷.۲ چالشهای سازمانی
- حاکمیت داده (Data Governance):
مطابق مقاله AgentNet (2025)، یکی از ریسکهای جدی در محیطهای بینسازمانی، نشت اطلاعات از حافظهها و پایگاههای اشتراکی عاملهاست. نیاز به زیرساختهای privacy-preserving و کنترل دقیق دادهها، یک ضرورت برای پیادهسازی صنعتی Agentic RAG محسوب میشود. - پذیرش نیروی انسانی:
در بسیاری از سازمانها، پذیرش عاملهای تصمیمیار با مقاومت مواجه است. موانعی همچون اعتماد پایین به خروجی مدلها، درک ناکافی از عملکرد سیستم و ترس از جایگزینی شغلی، موانعی روانی و فرهنگی محسوب میشوند. - هزینههای زیرساختی:
استقرار Agentic RAG نیازمند GPUهای قدرتمند، حافظههای پایدار، ابزارهای ارزیابی و چارچوبهای هماهنگی است که برای SMEها یا سازمانهای نوپا، چالشبرانگیز و پرهزینه است.
۷.۳ چالشهای اخلاقی و امنیتی
- همراستایی با ارزشها و قوانین:
علیرغم وجود لایه Alignment، تحقیقات (مانند مقاله Boraske et al., 2025) نشان میدهد که خروجیهای LLMها میتوانند حاوی سوگیری یا استنتاجهای نادرست باشند. توسعه مدلهای اخلاقمحور، استفاده از Retrieval-based context و کاهش نرخ تولید زبان سمی (toxic language) از راهکارهای کلیدی است. - حریم خصوصی و مسئولیتپذیری:
ذخیرهسازی اطلاعات حساس در حافظههای بلندمدت بدون رمزگذاری یا کنترل دسترسی مناسب میتواند نقض آشکاری از قوانین GDPR یا HIPAA باشد. همچنین، در صورت خطای عامل، هنوز چارچوب مشخصی برای تعیین مسئولیت قانونی (سازمان، توسعهدهنده، یا ارائهدهنده API) وجود ندارد.
۷.۴ آینده Agentic RAG
- ترکیب LLM با مدلهای SLM و QLM:
براساس رویکردهای نوین مانند sLA-tKGF (2024)، استفاده از LLMهای کموزن (SLM) یا کمدقت (QLM) در کنار LLMهای اصلی، علاوه بر کاهش هزینه، امکان استقرار در edge و تسهیل تعاملات سریع را فراهم میکند. - حرکت بهسوی استانداردسازی معماری:
تدوین چارچوبهای شفاف مشابه ISO/IEC برای معماری RAG در حال شکلگیری است. این استانداردها میتوانند شامل شاخصهای کیفی پاسخ، معیارهای alignment، پروتکلهای ارکستراسیون و الزامات حریم خصوصی باشند. - ادغام با IoT و همزادهای دیجیتال:
مطابق Xu et al. (2024)، Agentic RAG میتواند به موتور تصمیمگیری در محیطهای Cyber-Physical تبدیل شود؛ مثلاً در کارخانههایی که دادههای فیزیکی و مجازی (Digital Twin) بهطور همزمان تحلیل میشوند. - هوش مصنوعی توضیحپذیر (XAI):
مطالعه Reinhard et al. (2025) نشان داده که توضیحپذیری مبتنی بر analogical reasoning باعث افزایش اعتماد کاربر به پاسخ مدلها میشود. Agentic RAG آینده باید بتواند بهصورت شفاف، دلیل پاسخها، منابع، و روند استنتاج را ارائه دهد.
Agentic RAG در حال عبور از مرحله مفهومی به مرحله استقرار صنعتی است. موفقیت آن وابسته به توان حل چالشهای پیچیده در سطوح فنی، اخلاقی و سازمانی است. در صورت موفقیت، Agentic RAG میتواند نقشی مشابه ERPها در نسل قبلی فناوری ایفا کند؛ اما این بار برای مدیریت خودکار دانش، تصمیمگیری و انطباق در مقیاس گسترده.
۸. نتیجهگیری
تحول از RAG سنتی به Agentic RAG را میتوان نقطهعطفی در بلوغ فناوریهای زبانی و هوش مصنوعی سازمانی دانست. اگر معماری RAG توانست محدودیت «دانش ایستا» و پدیده «توهمزایی» مدلهای زبانی بزرگ را با ادغام بازیابی اطلاعات کاهش دهد، Agentic RAG یک گام فراتر نهاده و با افزودن مؤلفههایی همچون حافظه پویا، ارکستراسیون عاملها، ارزیابی مستمر و همراستایی اخلاقی، آن را به یک اکوسیستم تصمیمیار تبدیل کرده است (Singh et al., 2025).
در محیطهای پیچیدهای مانند صنایع سنگین، زنجیره تأمین، بانکداری یا سلامت دیجیتال، Agentic RAG نشان داده است که میتواند پاسخگویی واکنشی را به تحلیل زمینهمحور، تطبیقپذیر و اخلاقی تبدیل کند. مطالعات در حوزههای مختلف، از جمله سیستمهای چندعاملی صنعتی (Xiong et al., 2025) تا کاربرد در سلامت دیجیتال (Joy, 2025)، مؤید این ظرفیت تحولآفرین هستند.
با این حال، مسیر تکامل Agentic RAG با چالشهای فنی و نهادی روبهرو است. مقیاسپذیری پردازشی، حاکمیت داده، تضمین حریم خصوصی، و تبیین مسئولیت قانونی عاملها، موضوعاتیاند که نیازمند پژوهشهای بینرشتهای، تدوین استانداردهای صنعتی و همراستایی نهادی گستردهاند (Cerqueira et al., 2024).
چشمانداز آینده Agentic RAG در همگرایی آن با فناوریهایی نظیر مدلهای کموزن (SLM, QLM)، اینترنت اشیاء (IoT)، همزادهای دیجیتال و نیز پیشرفت در زمینه هوش مصنوعی توضیحپذیر (XAI) ترسیم میشود. چنین ترکیبی میتواند ستون فقرات نسل جدیدی از سامانههای شناختی باشد که نهتنها «پاسخ میدهند»، بلکه «فهمیده، یاد میگیرند، و تصمیم میسازند».
بهعبارت دیگر، Agentic RAG نه پایان یک مسیر، بلکه آغاز دورهای نوین از هوش مصنوعی سازمانی خودآگاه، چندعاملی و اخلاقمحور است؛ دورهای که میتواند همان نقشی را ایفا کند که ERPها در تحول دیجیتال دهههای گذشته ایفا کردند اما اینبار با تمرکز بر شناخت، تصمیمسازی و انطباق بلادرنگ.
مهدی عربزاده یکتا
30 شهریور 1404



دیدگاه خود را بنویسید